What Makes Good Primary Key?

The following question was recently asked on Quora:
How do I choose the primary key when there are two unique identifiers?
I disagree that choosing an integer over a
character field is the best answer for a Primary Key (PK). I am
providing a synopsis of the standards I defined in my Data Architecture Handbook and Data Management Framework. There is additional detail and diagrams under the section Data Design Considerations below.
Data Type
When I first started my 35-year+ career
as a data architect, it was true that integer fields were more
performant than character. This has not been true for a while yet the
belief still persists.
When I was building a major
(multi-terabyte) Enterprise Data Warehouse (EDW) for a law enforcement
system, I actually had to prove this to my DBAs via an extensive test
and the difference was nano-seconds. What was also proved is that fixed
length character is superior to variable-length character. Names and
descriptions are not good candidates for a PK for many reasons.
Key Length
Length not data type has an impact on index performance.
Composite Keys
However, my DBs and EDWs often use
composite PKs consisting of multiple columns and there is an
insignificant impact on performance. There is also the extra benefit of
being able to select by the highest order columns without having to know
the exact value you are looking for in the lower level columns; e.g.
find all country-subdivisions (state/province/canton…) for a selected
country.
Using a Composite Key is far better than using Junction Tables
(see Figure 2 below) in between every two related parent and child
tables. Increasing the number of tables joined in queries has a definite
performance hit and SQL coding complexity.
Two Unique Identifiers
So back to the original question of which
column to choose. Generally, having two columns that uniquely identify
each row is against Third Normal Form (3NF) Rules. 3NF is the basis on
which relational databases were originally designed by their founder,
Codd.
First you need to identify is what is the
origin and purpose of each column. Why was a second unique key added
to the table? I will give you one example I have come across a lot.
Many governmental departments used to create a table of Countries
identified by an arbitrary integer number. At a later date they added
the ISO two-character Country Code. In this case, the two-character
code is superior to the four or eight-byte integer. But not for the
reason of length.
Reference Code Tables
The point of ISO and other international
standards is to provide a set of code values that are independent of
language and can be exchanged between all countries and companies.
Therefore, it is the ISO, IATA, ITU, United Nations, Microsoft… code
that MUST be the primary key and must be
exchanged between organizations. Therefore, all Reference Code Tables
should use the code values defined by the international or
industry-specific standards (for instance, Microsoft defined the
Language codes).
Operational Data Tables
This is where a judgement call needs to
be made. Look at the purpose of each column and choose the one that
makes the most sense for your business. So, for a Purchase Order
table one would want to use the PO Number as defined by the business.
Generally, these keys are integer but not always. For instance, the
General Ledger usually looks like a number but is actually defined as
character by most financial accounting systems.
Data Design Considerations
Primary Key Choices
Natural Key
A natural key is formed from attributes that already exist in the real world.
[2] Especially if it is alphabetic, it can indicate the meaning of the data held in a row. An example in the figure below is
Country,
where a mnemonic acronym defined by ISO is used to identify each
country. The two-character ISO Country is pervasive as it is used by
the banking, travel, financial, foreign exchange (prefix for the ISO
Currency Code), and internet industries (used in web domains).
While some of these attributes will be
natural keys, many are auto-incrementing integer numbers such as
Purchase Order Number, Transaction Id, Contract Id, Invoice Number, and
Customer Id.
Surrogate Key
Surrogate Key is a unique identifier for
an object or row in a table and is frequently a sequential auto-number.
It has no relationship to the real-world meaning of the data held in a
row. Surrogate Key is essential for EDWs, which integrate data into a
table from multiple data sources. One cannot use the key defined in the
source system as it may conflict, be the same as a key in another
system and/or may be changed by the source system.
Data Modelling
If a database has been designed properly
there is no problem changing a primary key. The problem is that many
developers with limited data architecture experience are still designing
databases. In many instances, databases are not developed with
industry-strength Data Modelling (DM) tools. If a DM tool is used,
Referential Integrity business rules will be built right into the
database. There will be no need to do your own “coding”. The RI rules
will take care of changes or deletions, and when they are allowed.
Composite Keys
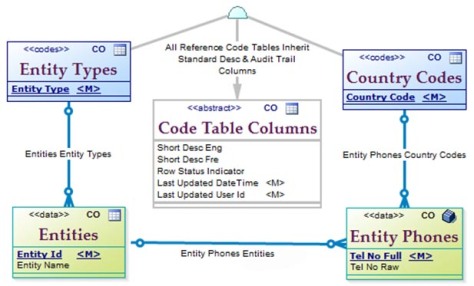
When a PK consists of two or more columns it is called a composite primary key. A composite key is required when one table is dependent on another table. For instance, Country Region (province, state, canton, département…) is only unique within (i.e. dependent on) Country. As shown in the figure below, the Country Region Codes table has a primary key consisting of Country and Ctry Region.
Figure 1: Composite Primary Key
Junction Tables
This following figure is an example of introducing an extraneous table into the model/database.
[1]
It provides no value-add and makes queries more complex and less
performant due to the extra joins. Junction tables lead to table
proliferation.

Figure 2: Junction Table between every Parent & Child Table
Identifying or Dependent Relationship
Instead directly link the tables using an identifying or dependent
relationship; in this case, phones belong to or are used by an entity. A
real plus is that a query can be made that finds all phones used by an
entity. You don’t have to know the phone numbers used by the entity.
This would be a single SELECT statement against a single table.
Figure 3: Child Table with Identifying Relationship
SQL Coding
Poorly coded SQL has probably the most significant impact on query performance.