A few weeks ago, we added a new slave to a 22TB MySQL server. The time to transfer the data, play innobackupex apply_log, the slave was already way behind the master. Things started to worsen during the weekend as the server performed a RAID check which slowed down the replication even more. With about 100 million writes a day on that cluster, we started the week with a good 500.000 seconds lag.
Replication lag is a frequent issue with loaded MySQL clusters. It can become critical when the lag gets too important: missing data when the slaves are used for reading, temporary data loss when losing the master… In our case, it blocks the cluster migration to GTID until the replication fully catches up.
Many people on the Web had the same problem but no one provided a comprehensive answer to that problem so I had to dig into MySQL documentation and internals to understand how to fix that.
First, the setup:
- Bi Xeon E5–2660 v3 20 core, 40 threads, 256GB RAM
- 24 7200 RPM hard disks of 4TB each, RAID 10.
- Percona Server 5.7.17–11–1 on Debian Jessie
- 100 million writes / day (~1150 queries / second)
- No reads, because of the lag
Multi-threaded replication
MySQL introduced multi-threaded replication with version 5.6. MTR has since then been improved with MySQL 5.7. It still needs to be used with caution when not using GTID or you might get into trouble.
First, we enabled parallel replication using all available cores on the server:
STOP SLAVE; SET GLOBAL slave_parallel_workers=40; START SLAVE;
You don't need to stop / start slave to change the slave_parallel_workers but according to the documentation MySQL won't use them until the next start slave.
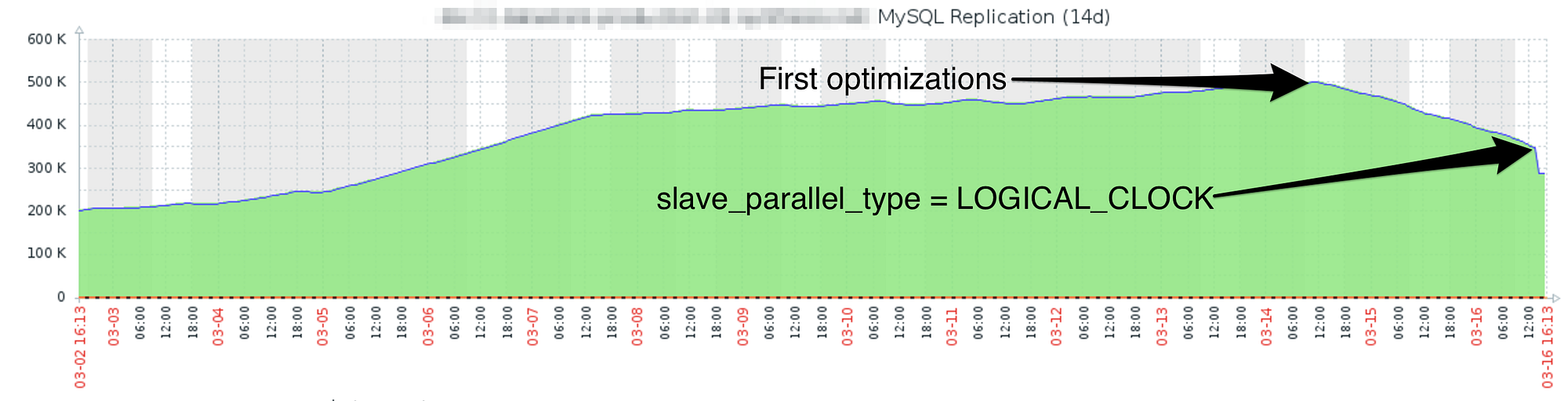
Parallel replication was useless first, as the host has only one database, and the default parallel replication type works on a database lock. We switched slave_parallel_type to LOGICAL_CLOCK, and the result was tremendous.
Transactions that are part of the same binary log group commit on a master are applied in parallel on a slave. There are no cross-database constraints, and data does not need to be partitioned into multiple databases.
STOP SLAVE; SET GLOBAL slave_parallel_type = LOGICAL_CLOCK; START SLAVE;
Please, flush the logs before leaving
Before we found the LOGICAL_CLOCK trick, we tuned the flushing a bit.
First, we make sure that MySQL never synchronizes the binary log to disk. Instead, we let the operating system do it from time to time. Note that sync_binlog default value is 0, but we used a higher value to avoid problems instead of crash.
SET GLOBAL sync_binlog=0;
Now comes the best part.
SET GLOBAL innodb_flush_log_at_trx_commit=2; SET GLOBAL innodb_flush_log_at_timeout=1800;
For ACID compliance, MySQL writes the contents of the InnoDB log buffer out to the log file at each transaction commit, then the log file is flushed to disk. Setting innodb_flush_log_at_trx_commit to 2 makes the flush happen every second (depending on the system load). This means that, in case of crash, innodb will have to replay all the non commited transactions (up you one second here).
innodb_flush_log_at_trx_commit=2 works in pair withinnodb_flush_log_at_timeout. With this setting, we ensure MySQL writes and flushes the log every 1800 second. This avoids impacting performances of binary log group commit, but you might have to replay up to 30 minutes of transaction in case of crash.
Conclusions
MySQL default settings are not meant to be used under a heavy workload. They aim at ensuring a correct replication work while ensuring ACID. After studying how our database cluster is used, we were able to decide that ACID was less a priority and catch up with our lagging replication.
Remember: if there's a problem, there's a solution. And if there's no solution, then there's no problem. So:
- Read the manual. The solution is often hidden there.
- Read the source when the documentation is not enough.
- Connect the dots (like innodb_flush_log_at_trx_commit + innodb_flush_log_at_timeout)
- Make sure you understand what you do
No comments:
Post a Comment